认证体系建设

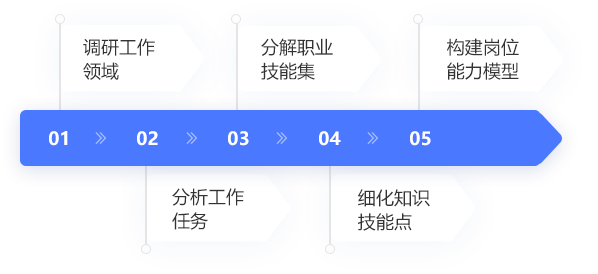
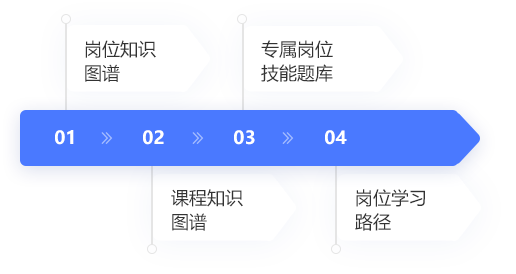
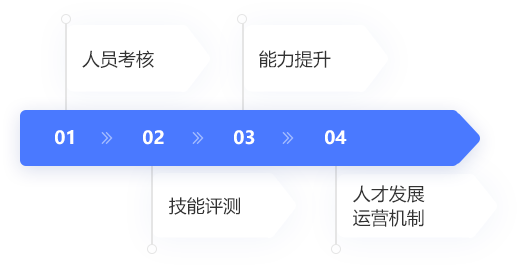
岗位能力模型
社会评价组织
专项技能认证
认证运营推广
课程体系建设
企业培训课程
高校专业课程
理论课程建设
实验资源建设
培训体系建设
岗位人才培训
企业产品培训
政策解读宣讲
线上线下活动
高校专业建设
人才培养方案
学生技能认证
专业核心课程
高校师资培训
实训教学平台






















































高质量数字人才培养专家
数智时代产教融合践行者


